Last updated on
Git statistics apps
In this lab, you will build two applications to fetch and visualize data about a git repository using many of the principles of software construction you have seen in the course so far.
They will be able to collect their data online, using the GitLab REST API or locally using the git log command.
One of them shows the contribution graph of a repository and the other one prints in the console the contributions of each author, grouped by months.
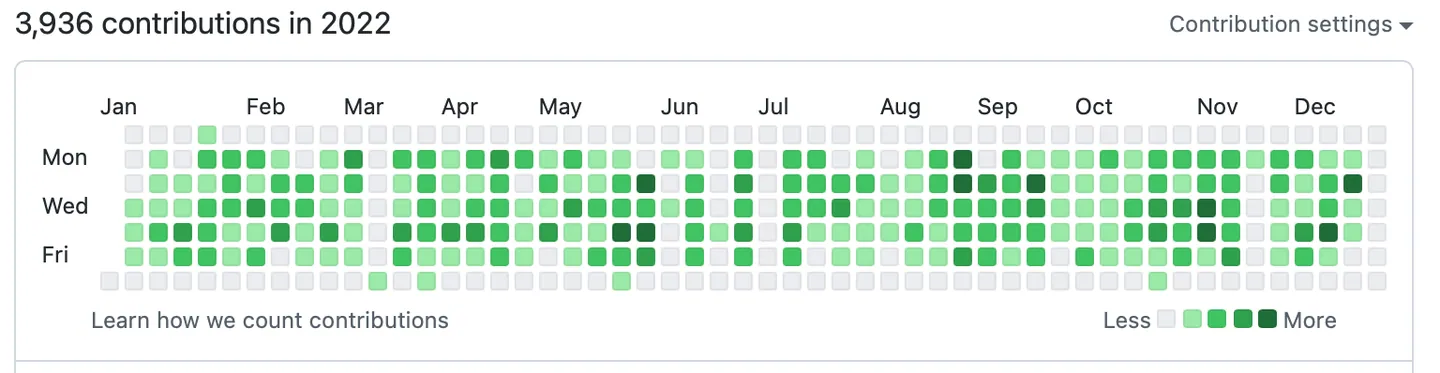 Github contributions graph example
Github contributions graph example
 Our app contributions graph example
Our app contributions graph example
90 contributions in 01.2024:
- Martin Odersky: 31
- Clément Pit-Claudel: 30
- Viktor Kuncak: 29
42 contributions in 02.2024:
- Matt Bovel: 16
- Viktor Kuncak: 14
- Clément Pit-Claudel: 12
55 contributions in 03.2024:
- Viktor Kuncak: 22
- Matt Bovel: 18
- Martin Odersky: 15
Our app contributions text example
This lab aims to exercise the following concepts and techniques:
- Working with code written by others
- Understanding the documentation of UNIX commands
- Understanding web APIs
- Understanding the advantages of Futures
Do not use Metals or VSCode
As an exercise and to help you succeed even if you face issues during the final exam, we recommend working without Metals, without worksheets, and without VSCode in this lab. Instead, use a plain text editor. If you prefer to stick with VSCode, disable the Metals extension and avoid worksheets.
To debug and develop your code without Metals, remember to run sbt compile frequently. This will help catch compilation issues early and prevent them from piling up. And, as an alternative to worksheets, test your code interactively using sbt console.
Logistics
-
This lab is not graded: you can submit it, but it does not count towards your course score.
-
You can get the materials for this lab by running:
git clone https://gitlab.epfl.ch/lamp/cs-214/gitstats.git -
Once you are done, submit the following files to Moodle:
src/main/scala/gitstats/data/GitlabRemoteRepository.scala src/main/scala/gitstats/data/GitLocalRepository.scala src/main/scala/gitstats/app/GitApp.scala
High-level overview
Our program is divided in three layers:
domainis the lowest layer. It contains the shared types used throughout our entire program. It doesn’t know anything about thedataandapplayers.datadepends ondomain. It abstracts away the process of fetching the raw data (online or locally) and transforms it as needed by the upper layer.appdepends on bothdataanddomain. It consumes the data provided by thedata. In our case, consuming the data means vizualising it either graphically or textually.
These layers keep our code organized with single responsability components. They also allow us to test almost all of our components independently by creating mock objects. For example, we can test our data sources with mock APIs to avoid doing HTTP requests during the tests (unexpected behavior and impossible in continuous integration) or running git log on an arbitrary repository.
APIs
Application Programming Interfaces (APIs) are constructs made available in programming languages to allow developers to create complex functionality more easily. They abstract more complex code away from you, providing some easier syntax to use in its place.
As a real-world example, think about the electricity supply in your house, apartment, or other dwellings. If you want to use an appliance in your house, you plug it into a plug socket and it works. You don’t try to wire it directly into the power supply — to do so would be really inefficient and, if you are not an electrician, difficult and dangerous to attempt. (source)
Some third-party websites such as GitLab provides some APIs to communicate with them in code and, for example, fetch some of their data.
A particular type of such API is the REST (Representational State Transfer) API. REST APIs are designed to be scalable, stateless (each request contains all the information needed), and use a consistent set of rules for communication. That’s why they are commonly used for data exchange and integration between different software systems on the web. (you can read more about REST APIs here)
GitLab REST API
GitLab provides a REST API to fetch any kind of data related to this service using HTTP requests. Take a brief look to the documentation page to grasp the main ideas.
Authentication
We need a way to authenticate ourselves to access our repository data. In this project, we will use personal/project/group access tokens. To authenticate yourself you can either add the token as a URL parameter (https://gitlab.example.com/api/v4/projects?private_token=<your_access_token>) or as an http header (Authorization: Bearer <your_access_token>). To ease up this process, the program will read the content of the CS214_GITSTATS_TOKEN environment variable and use this as a token. So whenever you’re running the remote program, make sure the token is correctly set.
You can set up a token for your webapp GitLab repository by adding a token under Settings > Access tokens. You need to at least tick the read_api scope.
Pagination
There could be thousands of commits made inside a repo, if you ask all of them in a single http request, the data will be too big to be sent as a single response. That’s why pagination exists: you ask for a page of data instead of all of it. Let’s imagine there is 100 commits in your repo, instead of asking for the 100 commits at the same time, you could make 10 requests for 10 commits and at the client level you’d merge the responses together.
Commits API
The endpoint https://gitlab.example.com/api/v4/projects/<your_project_id>/repository/commits is the entry point of the data we need. By making requests to this url, the GitLab API will respond with JSON-encoded data about the commits of our repository. Here is an example response:
[
{
"id": "ed899a2f4b50b4370feeea94676502b42383c746",
"short_id": "ed899a2f4b5",
"title": "Replace sanitize with escape once",
"author_name": "Example User",
"author_email": "user@example.com",
"authored_date": "2021-09-20T11:50:22.001+00:00",
"committer_name": "Administrator",
"committer_email": "admin@example.com",
"committed_date": "2021-09-20T11:50:22.001+00:00",
"created_at": "2021-09-20T11:50:22.001+00:00",
"message": "Replace sanitize with escape once",
"parent_ids": [
"6104942438c14ec7bd21c6cd5bd995272b3faff6"
],
"web_url": "https://gitlab.example.com/janedoe/gitlab-foss/-/commit/ed899a2f4b50b4370feeea94676502b42383c746",
"trailers": {},
"extended_trailers": {}
},
{
"id": "6104942438c14ec7bd21c6cd5bd995272b3faff6",
"short_id": "6104942438c",
"title": "Sanitize for network graph",
"author_name": "randx",
"author_email": "user@example.com",
"committer_name": "ExampleName",
"committer_email": "user@example.com",
"created_at": "2021-09-20T09:06:12.201+00:00",
"message": "Sanitize for network graph\nCc: John Doe <johndoe@gitlab.com>\nCc: Jane Doe <janedoe@gitlab.com>",
"parent_ids": [
"ae1d9fb46aa2b07ee9836d49862ec4e2c46fbbba"
],
"web_url": "https://gitlab.example.com/janedoe/gitlab-foss/-/commit/ed899a2f4b50b4370feeea94676502b42383c746",
"trailers": { "Cc": "Jane Doe <janedoe@gitlab.com>" },
"extended_trailers": { "Cc": ["John Doe <johndoe@gitlab.com>", "Jane Doe <janedoe@gitlab.com>"] }
}
]
Of course we don’t need all of this information, upon receival, we’ll discard the irrelevant data.
You can pass parameters to the above HTTP request such as ref_name or author_name. For example, https://gitlab.example.com/api/v4/projects/<your_project_id>/repository/commits?ref_name=myref&author_name=Arthur will fetch all the commits corresponding to a branch, tag or revision range “myref” made by “Arthur”.
Try it yourself ! Using curl, try to fetch the commits of your team’s webapp repository. You will need the project ID of your repository as well as the token you created.
Use the command curl --header "<your_header>" --url "https://gitlab.example.com/api/v4/projects/<your_project_id>/repository/commits" in your terminal to make a request to the GitLab API. Don’t forget to specify the token either in the header or as a URL parameter.
git log
To retrieve the commits locally, we use the git log command. Its output is highly customizable and we will use it at our advantage.
Take a look at the documentation for the following parameters and make sure you understand what they’re doing because they’re all used in this project:
--pretty[=<format>]--date=<format>--author=<pattern>--until=<pattern>--since=<pattern>-<number>
Implementation overview
Domain
Commit
Represents a git commit with its id, its title, its author name and email, the date on which it has been committed and its message.
Read about the difference between the author and the committer in the git log documentation
CommitsFilter
Represents a filter applicable to a query to fetch commits. It excludes some commits from the results. The different filters that exist in our project are:
Author(authorName): keeps only the commits with their author name equals toauthorNameRef(refName): keeps only the commits from the branch, tag or revision rangerefNameSince(date): keeps only the commits committed strictly afterdateUntil(date): keeps only the commits committed strictly beforedate
Dates are represented using the Joda Time library. Take a look at its documentation. In this project we mainly use the DateTime construct in the ISO 8601 format.
Data
APIs
At the lowest level of our project reside both local and remote APIs. They abstract away the low level requests to provide their result to the upper layers.
GitlabRemoteApi
Given a page and some commits filters, it executes the corresponding HTTP requests to fetch commits from GitLab. The URL that is used is constructed as follows: https://gitlab.epfl.ch/api/v4/projects/$projectId/repository/commits?filter1=FILTER1&filter2=FILTER2&filter3=FILTER3. It returns the raw HTTP response without transforming it.
GitLocalApi
Constructed for a specific repository location, using the git log command, it fetches the commits locally with some optional filters.
It returns the raw output of the command, you will need to understand how it is composed in order to parse it later.
Try to run the following command from any repository to observe its output: git log --pretty=format:%H%s%cn%ce%cd%b --date=format:%Y-%m-%dT%H:%M:%S.000%z --since="3 days ago".
Repositories
Just above APIs lie repositories. They take the raw results from the APIs and transform them into data for our domain. The goal is to abstract away the different methods to fetch the data and provide a unique interface returning Future[Seq[Commit]]:
def getCommits(maxCount: Option[Long] = None, filters: Seq[CommitsFilter] = Nil): Future[Seq[Commit]]
src/main/scala/gitstats/data/GitRepository.scala
It returns a future to allow multiple queries to be run simultaneously. By wrapping API requests around a future, they’re executed in a different thread, allowing a speedup when multiple of them are executed at once. We’ll get into more details about futures later.
GitLocalRepository
The local repository uses the raw output string of git log used by the local api to construct a Seq[Commit]. Your task is to implement GitLocalRepository.getCommits:
Don’t forget to wrap the API call in a future.
/** Returns a future containing maximum `maxCount` commits filtered with
* `filters`.
*
* @note
* Use `parseDateTime(String)` to go from a `String` to a `DateTime`
* @note
* Use `GitLocalApi.UNIT_SEP` and `GitLocalApi.RECORD_SEP` to split the
* output string of `api.getCommits`
* @param maxCount
* if `None` then fetch all the available commits else fetch maximum
* `maxCount` commits
* @param filters
* the filters to apply to the query
* @see
* https://git-scm.com/docs/git-log
*/
def getCommits(maxCount: Option[Long] = None, filters: Seq[CommitsFilter] = Nil): Future[Seq[Commit]] =
???
src/main/scala/gitstats/data/GitLocalRepository.scala
GitlabRemoteRepository
Using the raw output of the HTTP request made by the remote api, you need to construct a Seq[Commit]. The data source exposes its interface using a maxCount: Option[Int] parameter whereas the API use paging. You need to recursively ask for pages until you reach exactly maxCount results. By default a page is maximum 100 commits, however there may be less of them if they didn’t fit all in one HTTP response.
If the maxCount parameter is None, use Long.MaxValue as the maximal count of commits.
Here the use of the Future structure is not ideal. We wrap the entire call in a single future completing when all the pages have been fetched. Ideally, we would like the future to complete every time a page has been fetched, to already process it locally while we are fetching the next one online. We would like to have an asynchronous flow of data. Such a construct does not exist by default in Scala.
Think about why Seq[Future] isn’t a suitable alternatives for this behaviour.
Answer
To return a `Seq[Future]` we need to know in advance what are the futures to be called. However as the number of commits in a page may vary, we can't predict which calls to the API we'll execute
Your task is to implement GitlabRemoteRepository.getCommits:
/** Returns a future containing maximum `maxCount` commits filtered with
* `filters`.
*
* @note
* Use `extractJsonFrom(requests.Response)` to go from a
* `requests.response` to a `Seq[Commit]`
* @param maxCount
* if `None` then fetch all the available commits else fetch maximum
* `maxCount` commits
* @param filters
* the filters to apply to the query
* @see
* https://docs.gitlab.com/ee/api/rest/#pagination
*/
def getCommits(maxCount: Option[Long] = None, filters: Seq[CommitsFilter] = Nil): Future[Seq[Commit]] =
???
src/main/scala/gitstats/data/GitlabRemoteRepository.scala
App
The top most layer of our project are the applications. They use a data source to gather the relevant information, process and display them to the user.
You can pass a Seq[Query] where type Query = Seq[CommitsFilter] to their run methods to consume the commits of multiple queries (different filters).
They provide runSync(Seq[Query]), which will execute each query one after the other, i.e. it will wait for the result of the first one and consume it before starting the second one.
On the contrary, runAsync(Seq[Query]) will start all the queries at once and wait that all of them are done to consume their commits. It should run faster than runSync since you’re not waiting on each query result to start the next one.
trait GitApp
This common trait to apps can already define runSync and runAsync since it has access to the (defined in children) consumeCommits method.
runSync should get the commits from the data source for a single query at a time and then consume them. You can see the Await.result statement inside the loop, so that the method blocks until futureRes completes before going on to the next query.
runAsync should get the commits from the data source for all the queries simultaneously and then consume the queries one by one. You should use the auxiliary method queryAsync to fetch all the queries simultaneously, this method returns a Future[Seq[(Seq[Commit], Int)]], where the outer Seq[(Seq[Commit], Int)] represents each query result with its id.
Your task is now to implement both runSync and runAsync.
/** Consumes each query in `queries` synchronously (one after the other). */
def runSync(queries: Seq[Query]): Unit =
val TIMEOUT = 30.second
for
(query, id) <- queries.zipWithIndex
do
val futureRes =
???
Await.result(futureRes, TIMEOUT)
src/main/scala/gitstats/app/GitApp.scala
/** Consumes each query in `queries` asynchronously (all at the same time).
*
* @note
* Use `queryAsync` to get a future containing the results of all the
* queries
*/
def runAsync(queries: Seq[Query]): Unit =
val TIMEOUT = 30.second
val globFuture =
???
Await.result(globFuture, TIMEOUT)
/** Returns a future containing the results of all the `queries` along with
* their id.
*
* @note
* Take a look at `Future.sequence`
* @see
* https://dotty.epfl.ch/api/scala/concurrent/Future$.html
*/
def queryAsync(queries: Seq[Query]): Future[Seq[(Int, Seq[Commit])]] =
???
src/main/scala/gitstats/app/GitApp.scala
ConsoleGitApp
It prints in the console the contributions inside a repository of each author, grouped by months:
===== QUERY 0 =====
90 contributions in 01.2024:
- Martin Odersky: 31
- Clément Pit-Claudel: 30
- Viktor Kuncak: 29
42 contributions in 02.2024:
- Matt Bovel: 16
- Viktor Kuncak: 14
- Clément Pit-Claudel: 12
55 contributions in 03.2024:
- Viktor Kuncak: 22
- Matt Bovel: 18
- Martin Odersky: 15
GraphicalGitApp
It shows the contribution graph of a repository, i.e. how many commits have been committed each day:
Our app contributions graph example
The image is 7 pixels high, one pixel for each day of the week. Make sure that the image is full, i.e. each pixel is colored. For example, if the first commit is on a Friday, the first Monday to Thursday should be filled with the background color. The same applies for the end of the image (it should end on a Sunday).
The color of a pixel is a linear interpolation between the minimal color and the maximal color based on 1 / maxCommitsInADay * commitsThisDay. For example, if there are at most 10 commits in a day, and the current day has 2 commits, then the resulting color will be lerp(minColor, maxColor, 2 / 10). Minimal, maximal and background colors are defined in a ColorPalette object, feel free to create your own !
How to run the program
Once you implemented every feature, you can run your program !
Do not forget to set the environment variable for your authentication token: export CS214_GITSTATS_TOKEN=<your_token>.
By passing arguments, you can choose between the console and the graphical app, between running synchronously or asynchronously as well as between the remote and local data sources. By default, the local console app will run synchronously. The program accepts the following arguments:
--appchoose betweenconsoleorgraphicalapp, default isconsole--datasourcechoose betweenlocalorremotedata source, default islocal--pathset the absolute path to the repository for the local application, default is the current working directory--projectset the project id for the remote application, you can use thewebapp-libproject (31194)--asyncif present, will run asynchronously otherwise synchronously
For example:
- Run the local graphical app synchronously at a given path you’d run:
sbt run --app graphical --repository local --path <YOUR_ABSOLUTE_PATH> - Run the remote console app asynchronously for a given project id:
sbt run --async --app console --repository remote --project <YOUR_PROJECT_ID>
Feel free to modify the queries in gitstats.app.App.main and experiment with synchronicity versus asynchronicity. The more queries you include, the bigger the execution time difference should be.